
文本处理四剑客
命令grep:作用是对文本的行基于**模式(正则表达式)**进行过滤
命令sed:stream editor,文本编辑工具
命令awk:Linux上的实现gawk,文本报告生成器
文本处理四剑客之 grep
grep:Global search REgular expression and Print out the line
作用:文本搜索工具,根据用户指定的"模式"对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件(模式就是正则表达式)
官方帮助文档:https://man7.org/linux/man-pages/man1/grep.1.html
常用选项
-E #扩展正则,也可以使用egrep
-o #只显示匹配到的内容
-e #实现多个匹配项的拼接(或关系)
-n #显示匹配的行号
-r #递归处理,但不处理软链接
-l #不显示具体匹配到的内容,只显示匹配到的文件名
-i #忽略字符大小写
grep [选项] 模式 <文件>
#选项
-E #使用扩展正则表达模式(ERE),相当于使用egrep指令
-F #不支持正则表达式,相当于fgrep(将模式认为成字符串)
-G #将样式视为普通的表示法来使用
-P #支持Perl格式的正则表达式
-e #实现多个选项间的逻辑or关系。即将多个模式拼接在一起
-f #从文件中读取匹配规则,每行一条
-i #忽略字符的大小写
-w #匹配整个单词
-x #整行匹配
-s #不显示错误信息
-v #显示没有被匹配上的行,即取反
-B|--before-context=N #显示匹配到的字符串所在的行及其前N行
-A|--after-context=N #显示匹配到的字符串所在的行及其后N行
-C|--context=N #显示匹配到的字符串所在的行及其前后各N行
-N #与-C相同。匹配字符串所在行的前后各N行
--color=auto #对匹配到的内容高亮显示[always|never|auto]
-m|--max-count=N #只匹配N行。是行数不是次数。
-b|--byte-offset #显示匹配行第一个字符的编号
-n|--line-number #显示匹配的行号
-H|--with-filename #显示匹配行所在的文件名
-h|--no-filename #不显示匹配行所在的文件名
-o|--only-matching #仅显示匹配到的字符串
-q|--quiet|--silent #静默模式,不输出任何信息,但结果可以从变量$0拿
--binary-files=TYPE #指定二进制文件类型[binary|text|without-match]
-a|--text #同 --binary-files=text
-I #同 --binary-files=without-match
-d|--firectories=ACTION #怎样查找目录 [read|recurse|skip]
-D|--devices=ACTION #怎样查找设备文件 [read|skip]
-r|--recursive #递归目录,但不处理软链接
-R|--dereference-recursive #递归目录,会处理软链接
-L|--files-without-match #显示没有匹配上的文件名,只显示文件名
-l|--files-with-matches #显示匹配上的文件名,只显示文件名
-c|--count #统计匹配的行数。一行也可以被匹配多次
文本处理四剑客之 sed
sed的工作原理
sed 即 Stream EDitor,和 vi 不同,sed是行编辑器
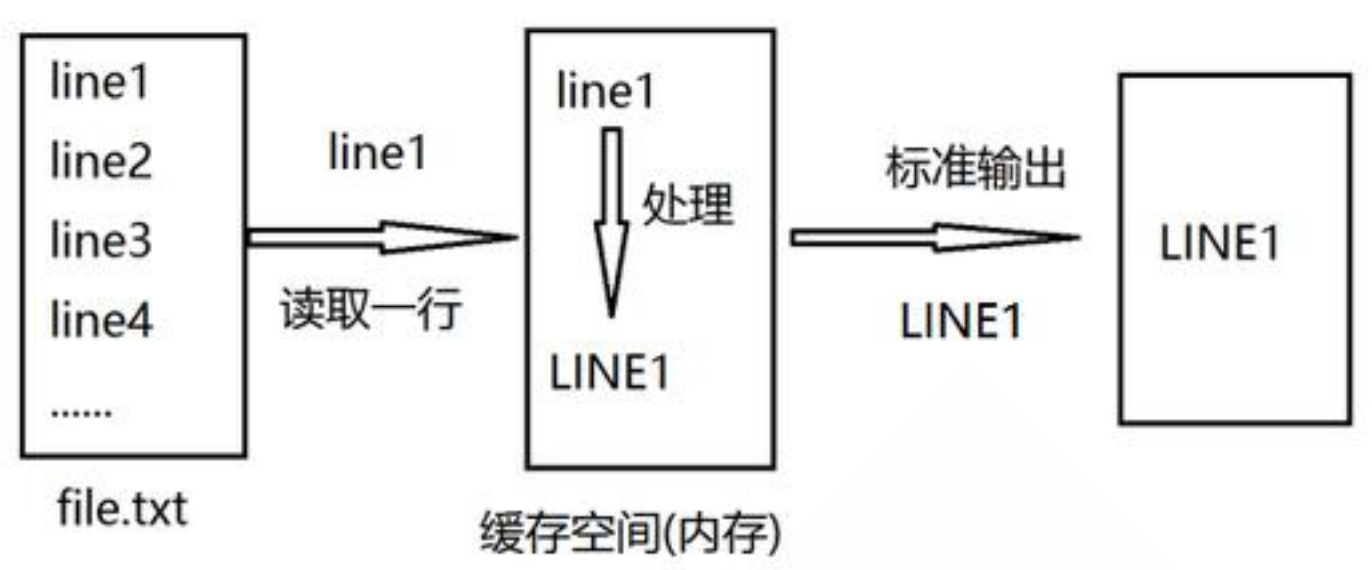
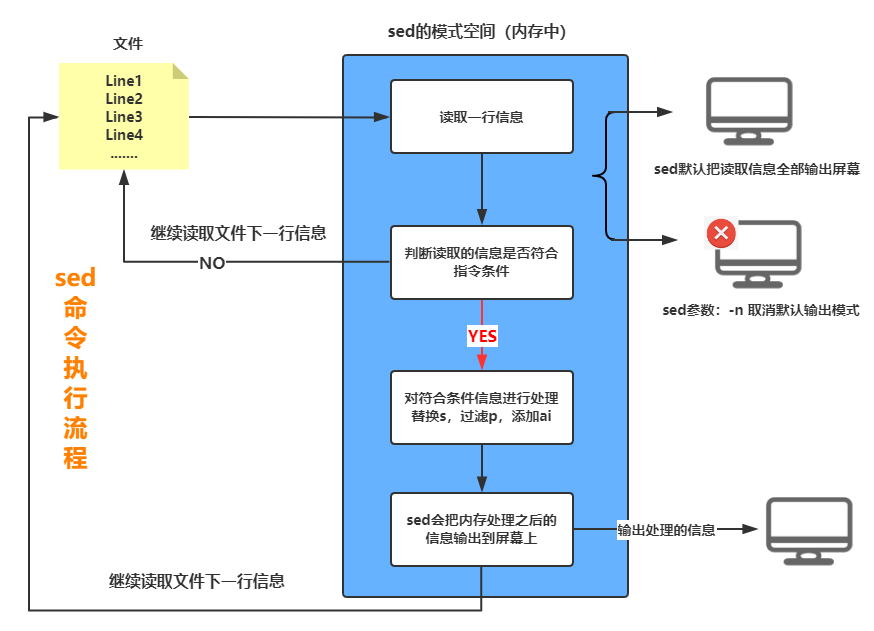
sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。
每当处理一行时,把当前处理的行存储在临时缓冲区 模式空间(Pattern Space)中,接着用sed命令处理缓冲区中的内容,处理完后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到处理完文件内容。
一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。
如果使用vi命令打开大文件,则会出现明显的卡顿现象,这是因为vi命令打开文件是一次性将文件加载到内存中,再一并打开。
sed就避免了这种情况,一行一行的处理。所以体感就会打开非常快,执行速度也很快。
相关文档:
- http://sed.sourceforge.net/
- https://man7.org/linux/man-pages/man1/sed.1.html
- http://www.gnu.org/software/sed/manual/sed.html
sed主要用来自动编辑一个或多个文件,具体作用如下:
- 可对文件添加数据的能力(增)
- 可对文件删除数据的能力(删)
- 可对文件修改数据的能力(改)
- 可对文件查询数据的能力(查)
sed的命令选项
sed [选项] {模式} <文件>
#选项
-n #关闭sed的默认全文输出。只输出script处理过的信息(使用p参数后才有)
-e #指定多个script指令,多点匹配
-f #从指定文件中读取script指令
-r #识别扩展正则表达式
-i<备份后缀名> #直接对原文本编辑。同时备份原文件(例如.bak)
sed 处理指令
#处理指令
p #输出script处理的数据行
Ip #I参数忽略过滤信息时的大小写
d #删除模式匹配到的行
a\ #在模式匹配到的行后面追加信息。再处理下一行
i\ #在模式匹配到的行前面追加信息。再处理下一行
c\ #替换匹配到的整行信息
w file #保存模式匹配到的行至指定文件(如果文件已存在会)
r file #在模式匹配到的行后将文件的文本内容插入进去
= #只显示模式匹配到的行号
! #取反
; #同参数-e
模式的格式:s/regexp/replacement/修饰符,支持使用其它分隔符。例:s###,s@@@
#修饰符
无修饰符 #只替换每一行第一个匹配到的文本
g #行内全面替换,不输出文本,Ng表示替换匹配到的前N行
p #打印替换后的文本
w #将替换后的信息写入一个文件
I #匹配时忽略字母大小写
sed 处理地址
#处理地址
无地址 #对文件全文处理
n #指定第几行处理
$ #处理文件最后一行
/regexp/ #正则匹配,匹配到的文本才处理。加上-r参数时,将支持扩展正则表达式
n,m #范围匹配,指定只对n行到m行的文本处理
n,+m #范围匹配,指定只对n行到n+m行文本处理
/regexp1/,/regexp2/ #范围匹配,指定只对regexp1匹配到行到regexp2匹配到行间进行处理
m,/regexp/ #范围匹配,指定只对n行到regexp匹配到的行进行处理
n~m #步长匹配,1~2表示从第一行开始,步长为2的跳跃(即1,3,5,7,9...)
sed 高级用法
sed 中除了模式空间,另外还支持保持空间(Hold Space),利用此空间,可以将模式空间中的数据,临时保存至保持空间,从而后续接着处理,实现更为强大的功能。
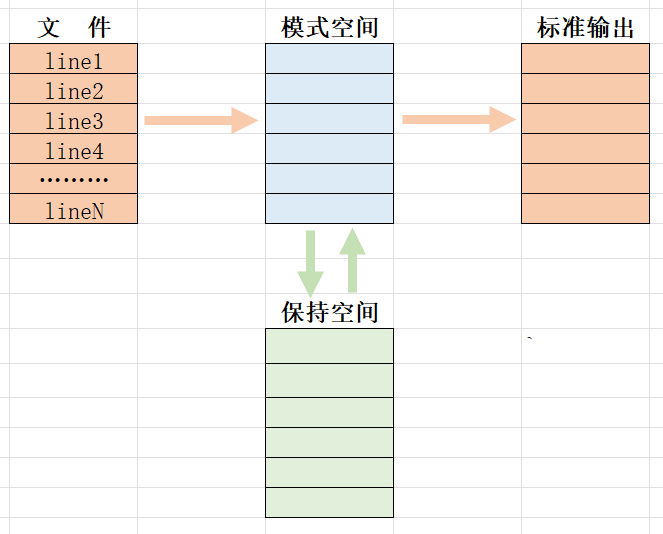
常见的高级命令
P 打印模式空间开端至第一个换行符\n的内容,并追加到默认输出之前
h 把模式空间中的内容覆盖至保持空间中
H 把模式空间中的内容追加至保持空间中
g 从保持空间去除数据覆盖至模式空间
G 从保持空间取出内容追加至模式空间
x 把模式空间中的内容与保持空间中的内容进行互换
n 读取匹配到的行的下一行覆盖至模式空间
N 读取匹配到的行的下一行追加至模式空间
d 删除模式空间中的行
D 如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使用合成的模式空间重新启动循环。如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环
文本处理四剑客之 awk
awk是由Aho,Weinberger,Kernighan三人打造的报告生成器。也可称作格式化文本输出。GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发维护,通常也称为GNU AWK。
awk有多种版本
- AWK:原先来源于AT & T实验室(贝尔实验室)的AWK
- NAWK:New awk,是AWK的升级版
- GAWK:即GNU AWK。所有的GNU/Linux发布版都自带GAWK,它与AWK和NAWK完全兼容
GNU AWK 用户手册文档:gnu文档链接
gawk:模式扫描和处理语言,可以实现以下功能。
- 文本处理
- 输出格式化的文本报表(这也是为什么实验室会制作这样一个工具)
- 执行算术运算
- 执行字符串操作
# centos7中的gawk
[root@centos7 ~]#ll `which awk`
lrwxrwxrwx. 1 root root 4 10月 18 2021 /usr/bin/awk -> gawk
[root@centos7 ~]#rpm -qi gawk
Name : gawk
Version : 4.0.2
Release : 4.el7_3.1
Architecture: x86_64
Install Date: 2021年10月18日 星期一 21时16分05秒
Group : Applications/Text
Size : 2435978
License : GPLv3+ and GPL and LGPLv3+ and LGPL and BSD
Signature : RSA/SHA256, 2017年06月29日 星期四 20时40分38秒, Key ID 24c6a8a7f4a80eb5
Source RPM : gawk-4.0.2-4.el7_3.1.src.rpm
Build Date : 2017年06月29日 星期四 05时52分50秒
Build Host : c1bm.rdu2.centos.org
Relocations : (not relocatable)
Packager : CentOS BuildSystem <http://bugs.centos.org>
Vendor : CentOS
URL : http://www.gnu.org/software/gawk/gawk.html
Summary : The GNU version of the awk text processing utility
Description :
The gawk package contains the GNU version of awk, a text processing
utility. Awk interprets a special-purpose programming language to do
quick and easy text pattern matching and reformatting jobs.
Install the gawk package if you need a text processing utility. Gawk is
considered to be a standard Linux tool for processing text.
awk语法说明
# 语法格式
awk [选项] '程序' 文件名(可接多个)
-F # fs指定输入分隔符,默认分隔符是匹配连续的空白符。支持正则匹配进行分割。如-F:
文本处理四剑客之 find
与find相似的还有一个locate。
find的特点
- 查找速度略慢
- 精确查找
- 实时查找
- 查找条件丰富
- 只能搜索用户具备读取和执行权限的目录
find [选项] [查找路径] [查找条件] [处理动作]
#查找路径:指定具体目标路径;默认为当前目录
#查找条件:指定的查找标准,可以是文件名、大小、类型、权限等标准进行;默认为找出指定路径下的所有文件
#处理动作:对符合条件的文件做操作,默认输出至屏幕
指定搜索目录的层级
-maxdepth N #最大搜索的目录深度,指定目录下的文件为第1级
-mindepth N #最小搜索的目录深度
先处理文件再处理目录
-depth #先处理文件
根据文件名和inode号查找
-name name #支持使用通配符。如: *, ?, [], [^],通配符要加双引号引起来
-iname name #不区分字母大小写
-inum number #按inode号查找
-samefile name #相同inode号的文件(后面接的文件如果不在当前目录下也需要指定路径)
-links n #链接数为n的文件
-regex "PATTERN" #以 正则表达式 来匹配整个文件路径,不只有文件名称
根据属主或属组查找
-user USERNAME #查找属主为指定用户(UID)的文件
-group GRPNAME #查找属组为指定组(GID)的文件
-uid UserID #查找属主为指定的UID号的文件
-gid GroupID #查找属组为指定的GID号的文件
-nouser #查找没有属主的文件
-nogroup #查找没有属组的文件
根据文件类型查找
-type TYPE #指定文件类型查找
#TYPE 值
f #普通文件
d #目录文件
l #符号链接文件
s #套接字文件
b #块设备文件
c #字符设备文件
p #管道文件
空文件或目录
-empty #空文件或空目录
组合条件
-a #与,多条件默认就是与关系。可省略
-o #或
-not|! #非
排除目录
-prune #跳过,排除指定目录,必须配合 -path使用
根据文件大小来查找
-size [+|-]N UNIT # N为数字,UNIT为常用单位。k,M,G,c(byte)等
# 10k 表示(9k,10k],大于9k且小于或等于10k
# -10k 表示[0k,9k],大于等于0k且小于或等于9k
# +10k 表示(10k,∞),大于10k
根据时间戳
# 以天为单位
-atime [+|-]N
-mtime [+|-]N
-ctime [+|-]N
#以分钟为单位
-amin [+|-]N
-mmin [+|-]N
-cmin [+|-]N
# 解释
N #表示[N,N+1),大于或等于N,小于N+1。表示第N天(或分钟)
+N #表示[N+1,∞),大于或等于N+1,表示N+1天之前(包括N+1天)
-N #表示[0,N),大于或等于0,小于N,表示N天(分钟)内
根据权限查找
-perm [/|-]MODE
MODE #精确权限匹配
/MODE #任何一位(u,g,o)对象的权限与设定的匹配(最低匹配一位)即可。表示或者(or)的关系
-MODE #每一类对象都必须同时拥有指定的权限。可以多,但不能少。表示与(and)关系
#MODE即是数字权限表示法。例:644
#注:如果权限位上设置的值是0,则表示不关注该角色权限
正则表达式
-regextype type #正则表达式类型。如果想使用扩展正则一定要使用
-regex pattern #正则表达式
# find 中的正则表达式类型
emacs #默认的类型。但与常用的正则表达式区别较大(GNU Emacs 风格)
posix-awk #类似awk命令。是 posix awk 风格正则
posix-basic #基本正则表达式(类似grep sed等不带选项的状态)
posix-egrep #扩展正则表达式
posix-extended #扩展正则表达式
处理动作
-print #默认的处理动作,显示至屏幕
-print0 #不换行输出,常用于配合xargs
-ls #对查找到的文件执行"ls -ils"命令格式输出(长格式输出)
-fls file #查找到的所有文件的长格式信息保存至指定文件中
-delete #删除查找到的文件(谨慎使用)
-ok COMMAND {} \; #对查找到的 每个文件 执行COMMAND命令。但每个文件在执行前会先询问
-exec COMMAND {} \; #对查找到的每个文件执行COMMAND命令。但不会询问
{} #用于引用查找到的文件名称自身(放在命令的参数位置)